

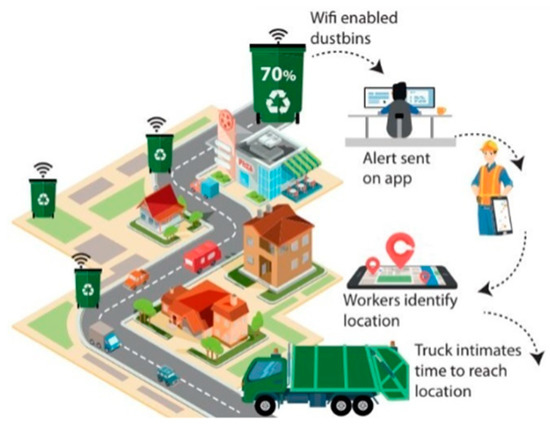
- INTRODUCTION
“Cleanliness is next to godliness” is said and believed for centuries.
Whether it may be a small home of four members or a locality cleanliness is of
equal importance. India is a huge and highly populated nation, effective
waste management is the major concern in maintaining the health and hygiene
of the people. The different types of wastes are domestic waste, industrial waste
, and environmental waste. The irregular management of such wastes is a root
cause for many human problems. Waste dumped in public places will
cause pollution, diseases and has adverse effects on the hygiene of living beings.
There is an ever-increasing amount of image data in the world, and the rate
of growth itself is increasing. Going beyond consumer devices, there are
cameras all over the world that capture images for automation purposes.
Automated processing of image contents is useful for a wide variety of image-
related tasks. For computer systems, this means crossing the so-called semantic
gap between the pixel level information stored in the image files and the human
understanding of the same images. Computer vision attempts to bridge this cap.

1.1 BACKGROUND
1.1.1 Machine Learning
Learning algorithms are widely used in computer vision applications.
Machine learning (ML) is the scientific study of algorithms and statistical
model that computer systems use to effectively perform a specific task without
using explicit instructions. There are different types of algorithms are used. A
typical way of using machine learning is supervised learning. After learning
from the examples, the algorithm is able to predict the annotations or labels of
previously unseen data. Classification and regression are the most important task
types. In unsupervised learning, the algorithm attempts to learn useful properties
of the data without a human teacher telling what the correct output should be.
Pre-processing the data into a new, simpler variable space is called feature
extraction. Since the training data cannot include every possible instance of the
inputs, the learning algorithm has to be able to generalize in order to handle
unseen data points.
1.1.2 Computer Vision
Computer vision deals with the extraction of meaningful information
from the contents of digital images or video. Today, machine learning is a
necessary component of many computer vision algorithms. Such algorithms can
be described as a combination of image processing and machine learning.
Object detection is one of the classical problems of computer vision. The
location and size is typically defined using a bounding box, which is stored in
the form of corner coordinates. The sub-image contained in the bounding box is
then classified by an algorithm that has been trained using machine learning.
1.1.3 Convolutional Neural Networks
A set of convolutional filters can be combined to form a convolutional
layer of a neural network. Successive convolutional layers form a convolutional
neural network (CNN). In order to reduce the data volume size use pooling layer
after a convolutional layer. This layer effectively down-samples the activation
maps. Typical pooling method is max-pooling. Max-pooling simply outputs the
maximum value within a rectangular neighbourhood of the activation map.
Another way of reducing the data volume size is adjusting the stride parameter
of the convolution operation. The stride parameter controls whether the
convolution output is calculated for a neighbourhood centred on every pixel of
the input image (stride 1) or for every nth pixel (stride n). The stride operation is
equivalent to using a fixed grid for pooling.
The convolutional layer typically includes a non-linear activation function,
such as a rectified linear activation function. The final hidden layers of a CNN
are typically fully-connected layersA convolutional network that does not
include any fully-connected layer, is called a fully convolutional network
(FCN).
2
Thejus Engineering College
Waste identification and alert message using machine learning
Project Report 2019
1.2 OBJECTIVES
The proposed project deals with the identification of different types of
wastes from images using machine learning algorithms and passing alert
messages to responsible authorities. It identifies any potential environmental
impacts from the generation of waste at the site. Other objective is to
recommend appropriate waste handling and disposal measures / routings in
accordance with the current legislative and administrative requirements; and to
categorise waste materials.
Here CNN and deep learning methods are used. A deep learning based
framework to localize and classify different types of wastes is used. An open
source implementation of Keras on Tensor flow is used .Waste images are
captured using mobile cameras, then processed for better quality and is fed to the
CNN. The images are then processed using AlexNet architecture and respective
activation functions are applied. The model outputs correct class of the wastes
and measures the accuracy. After proper classification, alert messages are sent to
the corresponding authorities.
1.2 PROBLEM STATEMENT
Waste images are captured using camera. Objects contained in image files
can be located and identified automatically. This is called object detection and is
one of the basic problems of computer vision. Convolutional neural networks
are currently the state-of-the-art solution for object detection. The main task of
this thesis is to review and test convolutional object detection methods. In the
theoretical part, the relevant literature is reviewed and studied how
convolutional object detection methods have improved in the past few years. In
the experimental part, how easily a convolutional object detection system can be
implemented in practice, test how well a detection system trained on general
image data performs in a specific task and explores both experimentally and
based on the literature, how the current systems can be improved is studied.
- SYSTEM ANALYSIS
2.1 EXISTING SYSTEM
In the existing waste management system, local government manage food
waste by deploying waste bins and employing multiple pickup business for waste
collection. However, the existing waste management method is based on flat rate,
that is a price structure that charges a single fixed fee, which causes environmental
problems and increases waste discharge because there are no restrictions on heavy
producers of waste and no incentives for lighter producers. Because waste
producers do not have a direct burden of expense for generating waste, it is
difficult for their waste amounts to be efficiently reduced. Moreover, the low
reliability of statistics on waste has caused difficulty in adjusting and managing
discharge amounts because a local government hires multiple pickup business for
waste collection, and each of them uses a different measuring method.
At present different machines are used to separate the waste into different
categories. Trommel separators/drum contains a rotating drum perforated with
holes in it. This separates wastes based on their sizes. When wastes are passed
through drum the particles with small size pass out through the holes and large
particles stay in the drum. Near Infrared Sensors (NIR) system uses the
reflectance property as its parameter for distinguishing various waste materials,
since different materials exhibit different reflective properties. X-ray technology
system puts into use the density property of various materials for differentiating
between them. Lastly, the manual method is the most widely used method for
separating wastes. Here the wastes are segregated manually by hand.
The above methods can work well in a small scale, but for large scale, these
methods are not very effective. It will be difficult to maintain these machines in
large scale. Keeping in mind the amount of waste generated now a days, large
number of such machines have to be bought. But buying and maintaining these
machines will prove to be excessively costly. Also the accuracy of these methods
are very low, especially the manual method which is prone to a lot of errors.

2.3 PROPOSED SYSTEM
The project deals with the identification of different types of wastes using
machine learning algorithms and passing alert messages to responsible authorities.
The alert messages contain the type of identified wastes so that the authorities can
take sufficient measures. A deep learning based framework is used to localize and
classify different types of wastes. An open source implementation of OverFeat on
Tensor flow was used as a starting point. Some modifications were done to
perform multi-classification. During training, these images occupy a considerable
amount of memory while loading their batches.
Convolutional Neural Networks have lots of advantages over other
methods. However, one of their drawbacks is the need for a large amount of
labeled training samples.The architecture of CNN used here is AlexNet .It
contains 5 convolutional layers and 3 fully connected layers. Relu is applied
after very convolutional and fully connected layer. Dropout is applied before the
first and the second fully connected layer.
2.3.1 First Layer
The input for AlexNet is a 227x227x3 RGB image which passes through
the firstconvolutional layer with 96 feature maps or filters having size 11×11 and
a stride of 4. The image dimensions changes to 55x55x96. Then the AlexNet
applies maximum pooling layer or sub-sampling layer with a filter size 3×3 and
a stride oftwo. The resulting image dimensions will be reduced to 27x27x96.
2.3.2 Second Layer
Next, there is a second convolutional layer with 256 feature maps having
size 5×5 and a stride of 1.Then there is again a maximum pooling layer with filter
size 3×3 and a stride of 2. This layer is same as the second layer except it has 256
feature maps so the output will be reduced to 13x13x256.
2.3.3 Third, Fourth and Fifth Layers
The third, fourth and fifth layers are convolutional layers with filter
size3×3 and a stride of one. The first two used 384 feature maps where the third
Waste identification and alert message using machine learning
Project Report 2019
used256 filters. The three convolutional layers are followed by a maximum
pooling layer with filter size 3×3, a stride of 2 and have 256 feature maps.
2.3.4 Sixth Layer:
The convolutional layer output is flatten through a fully connected layer
with 9216 feature maps each of size 1×1.
2.3.5 Seventh and Eighth Layers:
It consists of two fully connected layers with 4096 units.
2.3.6 Output Layer:
Finally, there is a softmax output layer ŷ with 1000 possible values.
3.2 OVERVIEW
Wastes may be generated during the extraction or processing of raw
materials, consumption of final products and human activities. They can thus be
classified as industrial waste, clinical waste and domestic waste. Improper
disposal of garbage has many hazards affecting all forms of life leading to
contamination of air, water and soil and also causes dangerous diseases to human
beings. The classification can be done by deep learning network.
Deep learning is an arising field of Machine learning in which
programmers do not need to analyze the shape of individual wastes. A deep
learning model automatically extracts features of the given input objects in a
training phase. In the inference phase, the trained model checks if the given image
contains the object that the model is trained with. Then, we train a deep learning
model with images of the identified frequently dumped wastes. The deep learning
approach is scalable because the model can be easily expanded to cover new
waste type by retraining the model with the new waste images. Instead of
monitoring everywhere, areas that effectively cover significant portions (hotspots)
of the illegal dumping incidents are targeted. To check if there is any waste in a
given spot, live images should be sent to a server that has sufficient computing
power to run object recognition software. However, sending images regardless the
existence of waste dumping incident may unnecessarily waste the network
resource and exacerbate the network congestion. Therefore, there should be a
solution that filters out clean images so that images are sent to the server only
when the illegal dumping actually occurs. Besides a server that has high
computing power to run the deep learning model, we also use an edge computing
station that is installed in individual hot spots. When a camera captures an image
of the site, the local computing station runs a deep learning model to measure the
probability of existence of the targeting wastes. Once there is sufficiently high
probability, the image is sent to the server to verify the illegal dumping.
3.5 ALGORITHM
Step 1: Start
Step 2: The system is switched on.
Step 3: The picture is loaded to the model
Step 4: The images are analysed with the trained data.
Step 5: Object identification takes place.
Step 6: A prediction is made based on the identification.
Step 7: The object is then classified based on the output data as plastic, glass,
metal, cardboard, paper.
Step 8: Then the alert indicating the type of waste is sent to the responsible
authorities

6.1 SOURCE CODE FOR TRAINING PHASE
import sys
importos
fromkeras.preprocessing.image import ImageDataGenerator
fromkeras import optimizers
fromkeras.models import Sequential
fromkeras.layers import Dropout, Flatten, Dense, Activation
fromkeras.layers.convolutional import Convolution2D, MaxPooling2D
fromkeras import callbacks
import time
start = time.time()
DEV = False
argvs = sys.argv
argc = len(argvs)
ifargc> 1 and (argvs[1] == “–development” or argvs[1] == “-d”):
DEV = True
if DEV:
epochs = 2
else:
epochs = 20
train_data_path = ‘data/train’
validation_data_path = ‘data/test’
“””
Parameters
“””
img_width, img_height = 512, 384
batch_size = 32
samples_per_epoch = 1000
validation_steps = 300
nb_filters1 = 32
nb_filters2 = 64
conv1_size = 3
conv2_size = 2
pool_size = 2
classes_num = 5
lr = 0.0004
model = Sequential()
model.add(Convolution2D(nb_filters1, conv1_size, conv1_size, border_mode
=”same”, input_shape=(img_width, img_height, 3)))
model.add(Activation(“relu”))
model.add(MaxPooling2D(pool_size=(pool_size, pool_size)))
model.add(Convolution2D(nb_filters2, conv2_size, conv2_size, border_mode
=”same”))
model.add(Activation(“relu”))
model.add(MaxPooling2D(pool_size=(pool_size, pool_size), dim_ordering=’th’))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation(“relu”))
model.add(Dropout(0.5))
model.add(Dense(classes_num, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’,
optimizer=optimizers.RMSprop(lr=lr),
metrics=[‘accuracy’])
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_path,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode=’categorical’)
validation_generator = test_datagen.flow_from_directory(
validation_data_path,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode=’categorical’)
“””
Tensorboard log
“””
log_dir = ‘./tf-log/’
tb_cb = callbacks.TensorBoard(log_dir=log_dir, histogram_freq=0)
cbks = [tb_cb]
model.fit_generator(
train_generator,
samples_per_epoch=samples_per_epoch,
epochs=epochs,
validation_data=validation_generator,
callbacks=cbks,
validation_steps=validation_steps)
target_dir = ‘./models/’
if not os.path.exists(target_dir):
os.mkdir(target_dir)
model.save(‘./models/model.h5’)
model.save_weights(‘./models/weights.h5’)
Calculate execution time
end = time.time()
dur = end-start
ifdur<60: print(“Execution Time:”,dur,”seconds”) elifdur>60 and dur<3600:
dur=dur/60
print(“Execution Time:”,dur,”minutes”)
else:
dur=dur/(60*60)
print(“Execution Time:”,dur,”hours”)
6.2 SOURCE CODE FOR TESTING
importos
importnumpy as np
fromkeras.preprocessing.image
import
ImageDataGenerator,
load_img,
img_to_array
fromkeras.models import Sequential, load_model
import time
start = time.time()
Define Path
model_path = ‘./models/model.h5’
model_weights_path = ‘./models/weights.h5’
test_path = ‘data/alien_test’
Load the pre-trained models
model = load_model(model_path)
model.load_weights(model_weights_path)
Define image parameters
img_width, img_height = 512, 384
Prediction Function
def predict(file):
x = load_img(file, target_size=(img_width,img_height))
x = img_to_array(x)
x = np.expand_dims(x, axis=0)
array = model.predict(x)
result = array[0]
print(result)
answer = np.argmax(result)
if answer == 1:
print(“Predicted: cardboard”)
elif answer == 0:
print(“Predicted: glass”)
elif answer == 2:
print(“Predicted: metal”)
elif answer == 3:
print(“Predicted: paper”)
elif answer == 4:
print(“Predicted: plastic”)
return answer
Department of CSE
32
Walk the directory for every image
for i, ret in enumerate(os.walk(test_path)):
for i, filename in enumerate(ret[2]):
iffilename.startswith(“.”):
continue
print(ret[0] + ‘/’ + filename)
result = predict(ret[0] + ‘/’ + filename)
print(” “)
Calculate execution time
end = time.time()
dur = end-start
ifdur<60: print(“Execution Time:”,dur,”seconds”) elifdur>60 and dur<3600:
dur=dur/60
print(“Execution Time:”,dur,”minutes”)
else:
dur=dur/(60*60)
print(“Execution Time:”,dur,”hours”)
6.3 SOURCE CODE FOR GUI
from PyQt5.QtWidgets import QMainWindow, QPushButton, QFileDialog,
QLineEdit, QPlainTextEdit
from PyQt5 import QtWidgets, QtGui, QtCore
from PyQt5.QtGui import QImage, QPalette, QBrush
from PyQt5.QtCore import QSize
import sys
import time
classMainWindow(QMainWindow):
def init(self):
QMainWindow.init(self)
font = QtGui.QFont(“Times”, 12)
font2 = QtGui.QFont(“Times”, 20, QtGui.QFont.Bold)
icon = QtGui.QIcon()
icon.addPixmap(QtGui.QPixmap(“icon.png”),
QtGui.QIcon.Normal,
QtGui.QIcon.Off)
self.setWindowIcon(icon)
self.setWindowTitle(“WASTE CLASSIFIER”)
self.setFixedSize(900,600)
Background Image Settings
oImage = QImage(“nature.png”)
sImage = oImage.scaled(QSize(900, 600)) # resize Image to widgets size
palette = QPalette()
palette.setBrush(10, QBrush(sImage))
self.setPalette(palette)
self.startButton = QPushButton(‘Start Service’, self)
self.startButton.setFont(font)
self.startButton.clicked.connect(self.startService)
self.startButton.setCursor(QtGui.QCursor(QtCore.Qt.PointingHandCursor))
self.startButton.move(500, 20)
self.startButton.resize(150, 30)
self.stopButton = QPushButton(‘Stop Service’, self)
self.stopButton.setFont(font)
self.stopButton.clicked.connect(self.download)
self.stopButton.setCursor(QtGui.QCursor(QtCore.Qt.PointingHandCursor))
self.stopButton.move(700, 20)
self.stopButton.resize(150, 30)
defstartService(self):
print(‘Start Service’)
options = QFileDialog.Options()
options |= QFileDialog.DontUseNativeDialog
fileName, _ = QFileDialog.getOpenFileName(self, “Select File”, “”,
“Image Files (*)”, options=options)
iffileName:
self.pixmap1 = QPixmap(fileName)
self.image_label1 = QLabel(self)
self.image_label1.setPixmap(self.pixmap1)
self.image_label1.resize(512,384)
self.image_label1.move(200,100)
self.image_label1.show()
waste_msg = waste+” Waste Detected”
self.cat_label = QLabel(self)
self.cat_label.move(100, 550)
self.cat_label.resize(300,30)
self.cat_label.setFont(self.font2)
self.cat_label.setText(waste_msg)
self.cat_label.setStyleSheet(“color:#ffffff”)
self.cat_label.show()
def download(self):
print(“print”)
if name == “main“:
app = QtWidgets.QApplication(sys.argv)
mainWin = MainWindow()
mainWin.show()
sys.exit(app.exec_())
6.4 SOURCE CODE FOR SENDING ALERT MESSAGES
importsmtplib
fromemail.mime.multipart import MIMEMultipart
fromemail.mime.text import MIMEText
fromemail.mime.base import MIMEBase
from email import encoders
fromaddr = “nithinkurian777@gmail.com”
toaddr = “nithinkurian777@gmail.com”
msg = MIMEMultipart()
msg[‘From’] = fromaddr
msg[‘To’] = toaddr
msg[‘Subject’] = “Subject of the Mail”
body = “Body_of_the_mail”
msg.attach(MIMEText(body, ‘plain’))
filename = “File_name_with_extension”
attachment = open(“test.txt”, “rb”)
p = MIMEBase(‘application’, ‘octet-stream’)
p.set_payload((attachment).read())
encoders.encode_base64(p)
p.add_header(‘Content-Disposition’, “attachment; filename= %s” % filename)
msg.attach(p)
s = smtplib.SMTP(‘smtp.gmail.com’, 587)
s.starttls()
s.login(fromaddr, “login@123”)
text = msg.as_string()
s.sendmail(fromaddr, toaddr, text)
s.quit()
- ADVANTAGES AND DISADVANTAGES
8.1 ADVANTAGES
Applying smart waste management process to the city optimizes
management, resources and costs which makes it a “smart city”.
It helps administration to generate extra revenue by advertisements on
smart devices.
Proper implementation of this method can motivate people to practice
proper waste management.
A CNN architecture makes it possible to predict objects and faces in
images using industry benchmark datasets with up to 95% accuracy,
greater than human capabilities which stand at 94% accuracy .
The best thing is there is no need of feature extraction. The system learns
to do feature extraction and the core concept of CNN is, it uses
convolution of image and filters to generate invariant features which are
passed on to the next layer. The features in next layer are convoluted
with different filters to generate more invariant and abstract features and
the process continues till one gets final feature / output (let say face of X)
which is invariant to occlusions.
It saves time and money
It sends alert messages with details of type of waste,image of the
waste,etc to the responsible authorities, so that the authorities can take
necessary actions without visiting the place.
8.2 DISADVANTAGES
For an average image with hundreds of pixels and three channels, a neural
network will generate millions of parameters, which can lead to
overfitting.
The model would be very computationally intensive.
The training has to be provided to the people involved in the smart waste
management system.
Require high processing power. Models are typically trained on high-cost
machines with specialized Graphical Processing Units (GPUs).
Can fail when images are rotated or tilted, or when an image has the
features of the desired object, but not in the correct order or position.
Processing & Storing-it requires large amount of memory to store training
data and images.
Image Size & Quality-the relative size of input image is compared with
the size of trained image and if the requirements are not met, then the
image will be cut shorted which affects its quality.
It is impossible to inspect the type of the waste present inside the cover.